Privacy-Preserving Data Processing Techniques Based on Cryptography
The
rapid development of Internet provides us with tremendous opportunities
for collaborative data computations. Many organizations and companies
want to do joint work to get mutual benefit of their individual data.
At the same time, with the powerful data processing techniques, it also
can bring some privacy violation problems. In the real world, many
organizations and individuals may have concern on their own privacy,
and may be reluctant to share their own data for data mining unless
their privacy will not be violated or misused by other parties. For
this reason, a privacy-preserving system is needed to execute the
collaborative data processing.
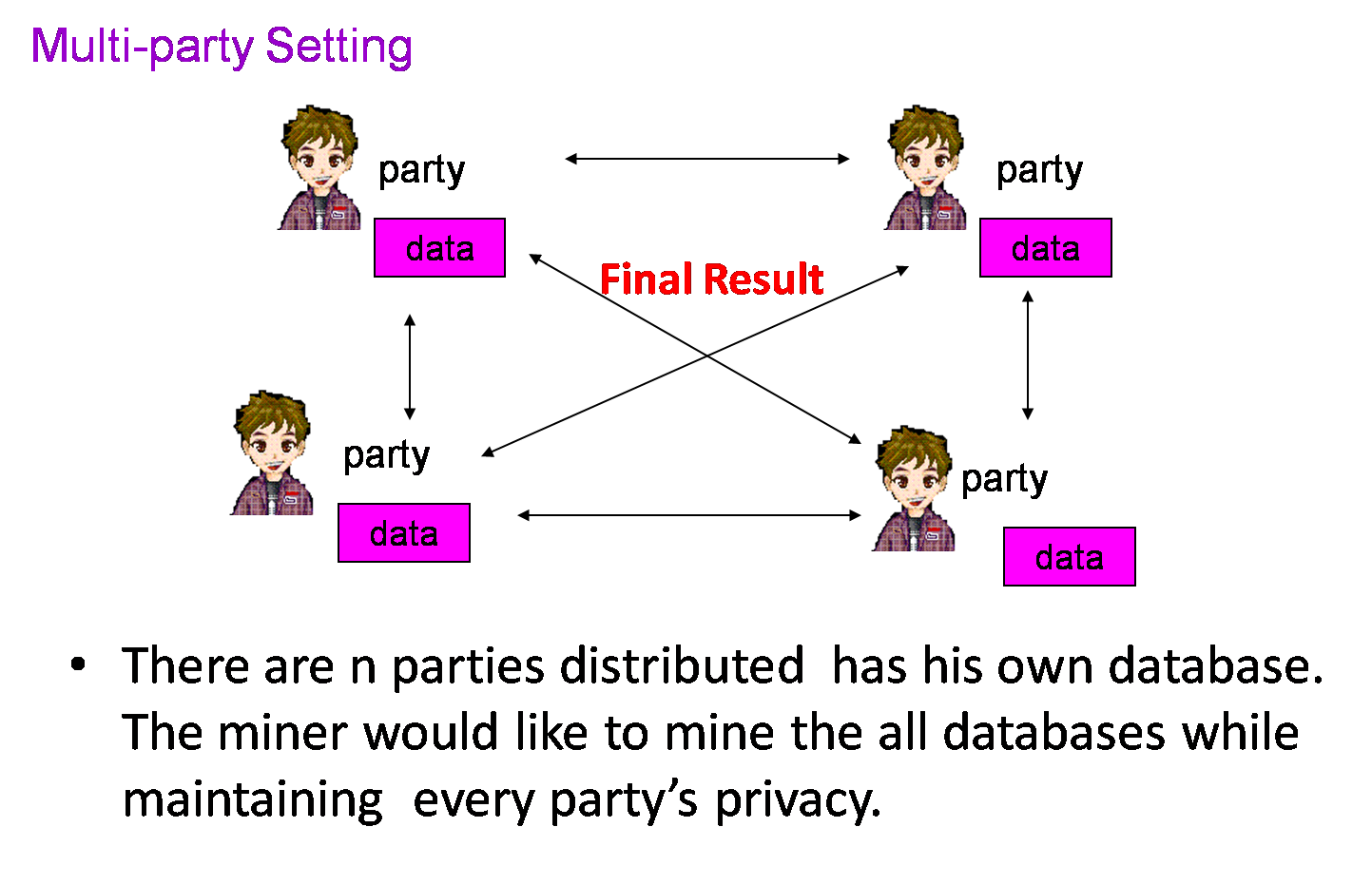
Our research is based on
cryptographic secure multi-party computation techniques. It allows a
set of n players to securely compute any agreed function on their
private inputs and the corrupted players do not learn any information
about the other players' inputs. That is, the only information learned
by one party participating in the computation is the one that can be
learned from the final output results of the collaborative data
processing.
Related Papers:
1.
Chunhua Su, Jianying Zhou, Feng Bao, Tsuyoshi Takagi, Kouichi Sakurai,
"Two Party Privacy-Preserving Agglomerative Document Clustering", 3rd
Information Security Practice and Experience Conference,
LNCS6477, pp. 193-208, HongKong, May, 2007.
2. Chunhua Su, Feng
Bao, Jianying Zhou, Tsuyoshi Takagi, Kouichi Sakurai,
"Privacy-Preserving Two-Party K-Means Clustering Via Secure
Approximation", The 2007 IEEE International Symposium on Data Mining
and Information Retrieval, pp.385-391, Niagara Falls, Canada. May, 2007.
3.
Chunhua Su, Feng Bao, Jianying Zhou, Tsuyoshi Takagi, and Kouichi
Sakurai. "A New Scheme for Distributed Density Estimation based
Privacy-Preserving Clustering". (AReS'08), Proceedings of 2008
International Conference on Availability, Reliability and Security, pp.
48-57, IEEE Computer Society Press, Barcelona, Spain, March 2008.